Tracking Stan sampling progress in Shiny
A simple approach using callr
Introduction
The previous post demonstrates the use of pre-compiled Stan models in interactive R Shiny applications to avoid unnecessary Stan model (re-)compilation on application start-up. In this short follow-up post we go a step further and tackle the issue of tracking the Stan model sampling progress itself in a shiny-application. The idea, mainly inspired by this blog post, is to execute the Stan model sampling in a separate background R process using the convenient callr-package to avoid blocking of the shiny-application.
Demo Shiny-app
For illustration purposes, we start from the basic shiny-app in the previous post that fits a simple linear model in Stan and plots the sampled posteriors:
library(shiny)
ui <- fluidPage(
sidebarLayout(
sidebarPanel(
numericInput("N", label = "N", value = 10)
),
mainPanel(
plotOutput("posteriors")
)
)
)
server <- function(input, output, session) {
## draw samples
draws <- reactive({
N <- input$N
rstan::sampling(
object = shinyStanModels:::stanmodels[["lm"]],
data = list(N = N, x = seq_len(N), y = rnorm(N, seq_len(N), 0.1)),
chains = 2,
iter = 1000
)
})
## plot histograms
output$posteriors <- renderPlot({
req(draws())
op <- par(mfrow = c(1, 2), cex = 1.25)
hist(rstan::extract(draws(), "alpha")[[1]], main = bquote("Posterior samples"~alpha), xlab = expression(alpha))
hist(rstan::extract(draws(), "beta")[[1]], main = bquote("Posterior samples"~beta), xlab = expression(beta))
par(op)
})
}
shinyApp(ui = ui, server = server)
Note: here the pre-compiled "lm" Stan model is called from a dummy R-package shinyStanModels as explained previously to avoid model recompilation every time the shiny-app is launched.
Shiny-app blocking
By increasing the number observations \(N\), we also increase the execution time of the MCMC sampling process. Setting e.g. \(N = 500\), it already takes quite a while for the computations to complete1. Unfortunately, there is no way to tell from the shiny-app whether the sampling iterations are progressing quickly or still require a long time to finish. In an interactive R-session, the progress of the sampling iterations across individual chains is either printed to the console (that is, the current stdout connection) or to a temporary file when multiple chains are being sampled in parallel. It would be great if we could divert these progress messages to the shiny-app itself, so that the sampling iterations can be tracked in real-time in the same way as in any interactive R-session.
A first idea that comes to mind is to make use of shiny’s reactivePoll() or reactiveFileReader() to periodically read the contents of the temporary progress file generated by Stan, and display these contents in reactively in the shiny-app. The problem, however, is that due to shiny’s synchronous reactive nature the shiny-app is effectively blocked while executing the sampling process, and the reactiveFileReader() will only have a chance to read the progress file when the model sampling is already finished, thereby defeating its purpose.
Instead, we have to somehow detach the slow model sampling process from the main shiny-app process so that both processes do not interfere with each other and the shiny-app is free to execute other requests. In fact, what is needed is a way to launch the sampling process in a separate background R-process, and, as it turns out, this is exactly what is provided by the convenient callr-package.
Unblocking a shiny-app with callr
In order to execute the Stan model sampling procedure in a separate R-process, we wrap the call to rstan::sampling() in a function and pass it to the func argument of callr::r_bg(). The function is evaluated in a background R-process and may take a long time to complete, but callr::r_bg() immediately returns control to the current R-process so that it is free to perform other operations:
library(callr)
## launch job in separate R process
r_process <- r_bg(
func = function(N) {
rstan::sampling(
object = shinyStanModels:::stanmodels[["lm"]],
data = list(N = N, x = seq_len(N), y = rnorm(N, seq_len(N), 0.1)),
open_progress = FALSE,
chains = 2,
iter = 1000
)
},
args = list(N = 500)
)
## the process object is returned immediately
## and can be polled from the current R process
r_process
#> PROCESS 'R', running, pid 31672.
## check if job is still running
r_process$is_alive()
#> [1] TRUE
## result is not yet available
tryCatch(r_process$get_result(), error = function(e) e$message)
#> [1] "Still alive"
## extract the result when the job is finished
system.time({
r_process$wait()
})
#> user system elapsed
#> 22.239 0.099 22.247
r_process
#> PROCESS 'R', finished.
r_process$get_result()
#> Inference for Stan model: lm.
#> 2 chains, each with iter=1000; warmup=500; thin=1;
#> post-warmup draws per chain=500, total post-warmup draws=1000.
#>
#> mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
#> alpha 0.02 0.00 0.01 0.00 0.01 0.02 0.03 0.04 248 1.01
#> beta 1.00 0.00 0.00 1.00 1.00 1.00 1.00 1.00 338 1.01
#> sigma 0.10 0.00 0.00 0.09 0.10 0.10 0.10 0.10 293 1.00
#> lp__ 909.03 0.07 1.23 905.93 908.46 909.40 909.93 910.40 296 1.01
#>
#> Samples were drawn using NUTS(diag_e) at Mon Apr 12 09:00:15 2021.
#> For each parameter, n_eff is a crude measure of effective sample size,
#> and Rhat is the potential scale reduction factor on split chains (at
#> convergence, Rhat=1).Note: launching a separate R-process does not necessarily require a multi-core processor and also works using only a single-core processor. On the other hand, the R-session does need to have sufficient permission/rights to launch a separate R-process on the system.
Demo Shiny-app (continued)
In a first step, we update the shiny-app by wrapping the rstan::sampling() call in a call to callr::r_bg() so that the execution of the model sampling no longer blocks the shiny-app process. Using the stdout argument of callr::r_bg() we can divert2 all messages generated by rstan::sampling() (and printed to stdout) to a temporary file tfile.
Whenever the number of observations \(N\) is changed and a new background R-process is launched, we instruct the shiny-app to start polling the process object (r$bg_process) by updating the reactive value r$poll. This will trigger an observer to: (1) read and assign the contents of the progress file tfile to a reactive value r$progress whenever the progress file has been modified; (2) check if the background process has finished executing and if this is the case retrieve the sampling results. The observer will be re-executed every second and only stops re-executing when the background process is no longer alive and r$poll has been turned off (i.e. set to FALSE).
The progress messages can now be rendered in real-time in the shiny-app by simply pasting the contents of the reactive value r$progress. The posterior histograms only need to be updated whenever new sampling results are available in the reactive value r$draws.
In short, we can summarize the updated shiny-app with the following graph:
More importantly, the updated shiny-app –including model sampling progress– now looks as follows:
library(shiny)
ui <- fluidPage(
sidebarLayout(
sidebarPanel(
numericInput("N", label = "N", value = 10)
),
mainPanel(
plotOutput("posteriors"),
hr(),
## limit the height of the progress message box
tags$head(tags$style("#progress{overflow-y:scroll; max-height: 500px;}")),
verbatimTextOutput("progress")
)
)
)
server <- function(input, output, session) {
## file to write progress
tfile <- tempfile(fileext = ".txt")
## reactive values
r <- reactiveValues(
progress_mtime = -1
)
observeEvent(input$N, {
## start sampling in background process
r$bg_process <- callr::r_bg(
## this is a long running computation
func = function(N) {
rstan::sampling(
object = shinyStanModels:::stanmodels[["lm"]],
data = list(N = N, x = seq_len(N), y = rnorm(N, seq_len(N), 0.1)),
open_progress = FALSE,
iter = 1000,
chains = 2
)
},
args = list(N = input$N),
stdout = tfile,
supervise = TRUE
)
## start polling bg process
r$poll <- TRUE
})
## observe status of bg process
observe({
req(r$bg_process, r$poll)
## keep re-executing observer as
## long as bg process is running
invalidateLater(millis = 1000, session)
## read current progress if file is modified
mtime <- file.info(tfile)$mtime
if(mtime > r$progress_mtime) {
r$progress <- readLines(tfile)
r$progress_mtime <- mtime
}
## extract draws when bg process is finished
if(!r$bg_process$is_alive()) {
r$draws <- r$bg_process$get_result()
r$poll <- FALSE ## stop polling bg process
}
})
## plot histograms
output$posteriors <- renderPlot({
req(r$draws)
op <- par(mfrow = c(1, 2), cex = 1.25)
hist(rstan::extract(r$draws, "alpha")[[1]], main = bquote("Posterior samples"~alpha), xlab = expression(alpha))
hist(rstan::extract(r$draws, "beta")[[1]], main = bquote("Posterior samples"~beta), xlab = expression(beta))
par(op)
})
## print progress
output$progress <- renderText({
req(r$progress)
paste(r$progress, collapse = "\n")
})
}
shinyApp(ui = ui, server = server)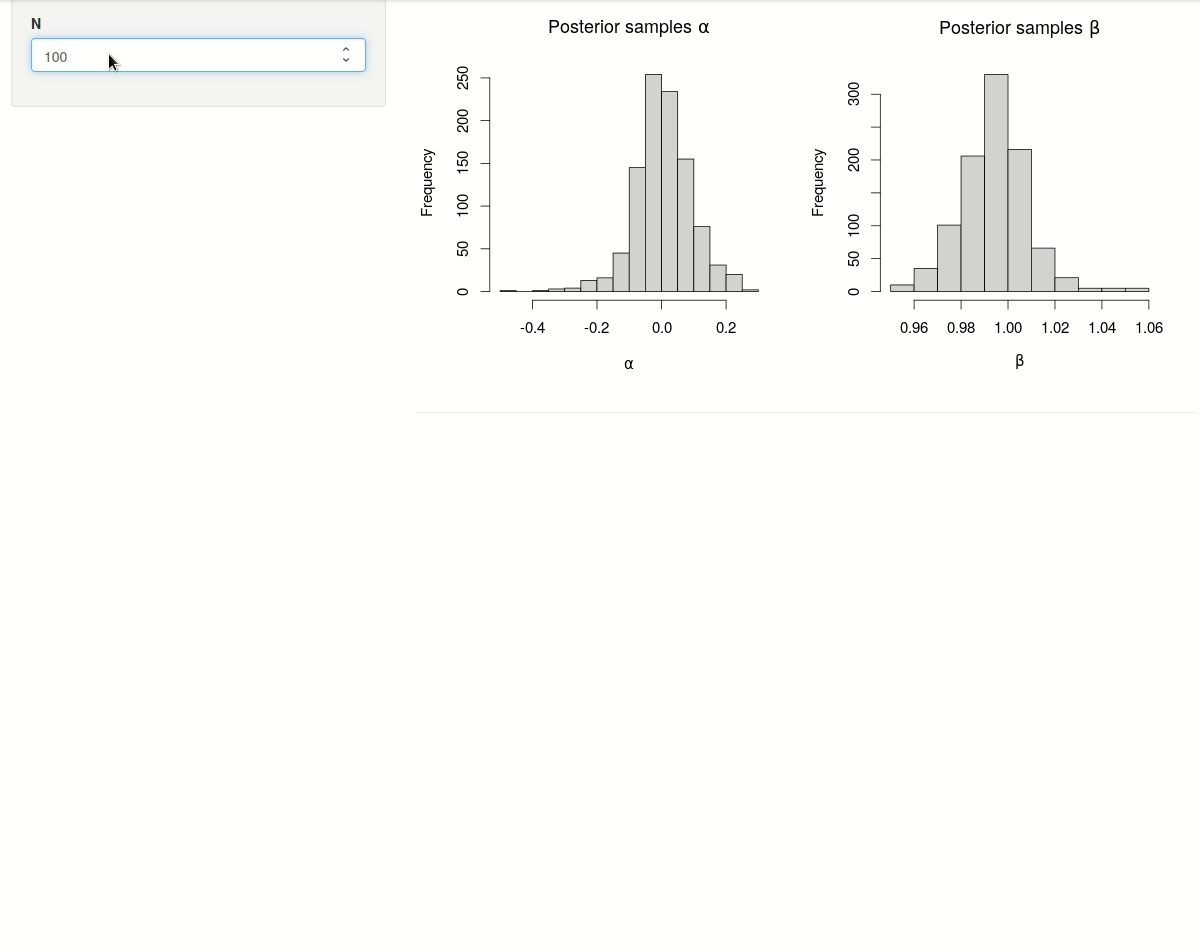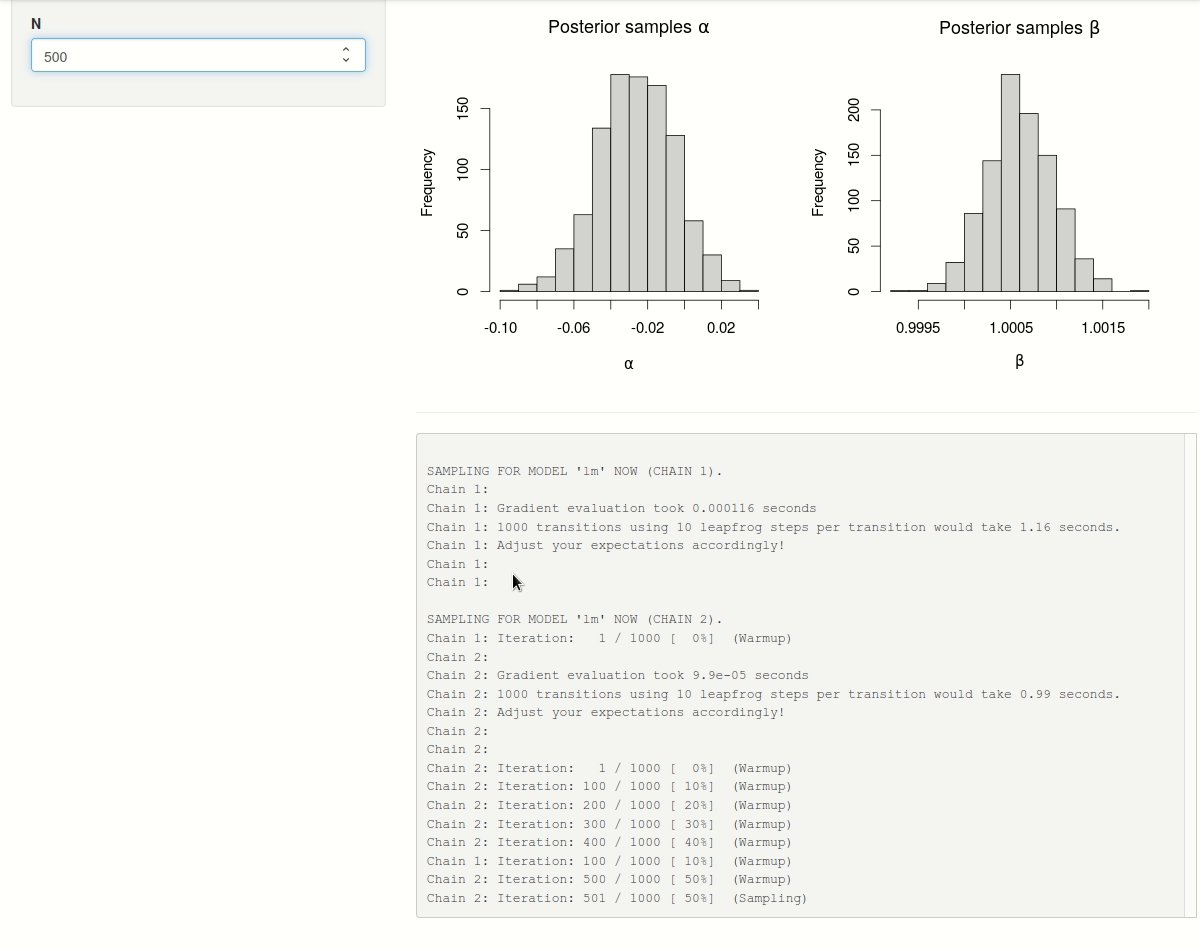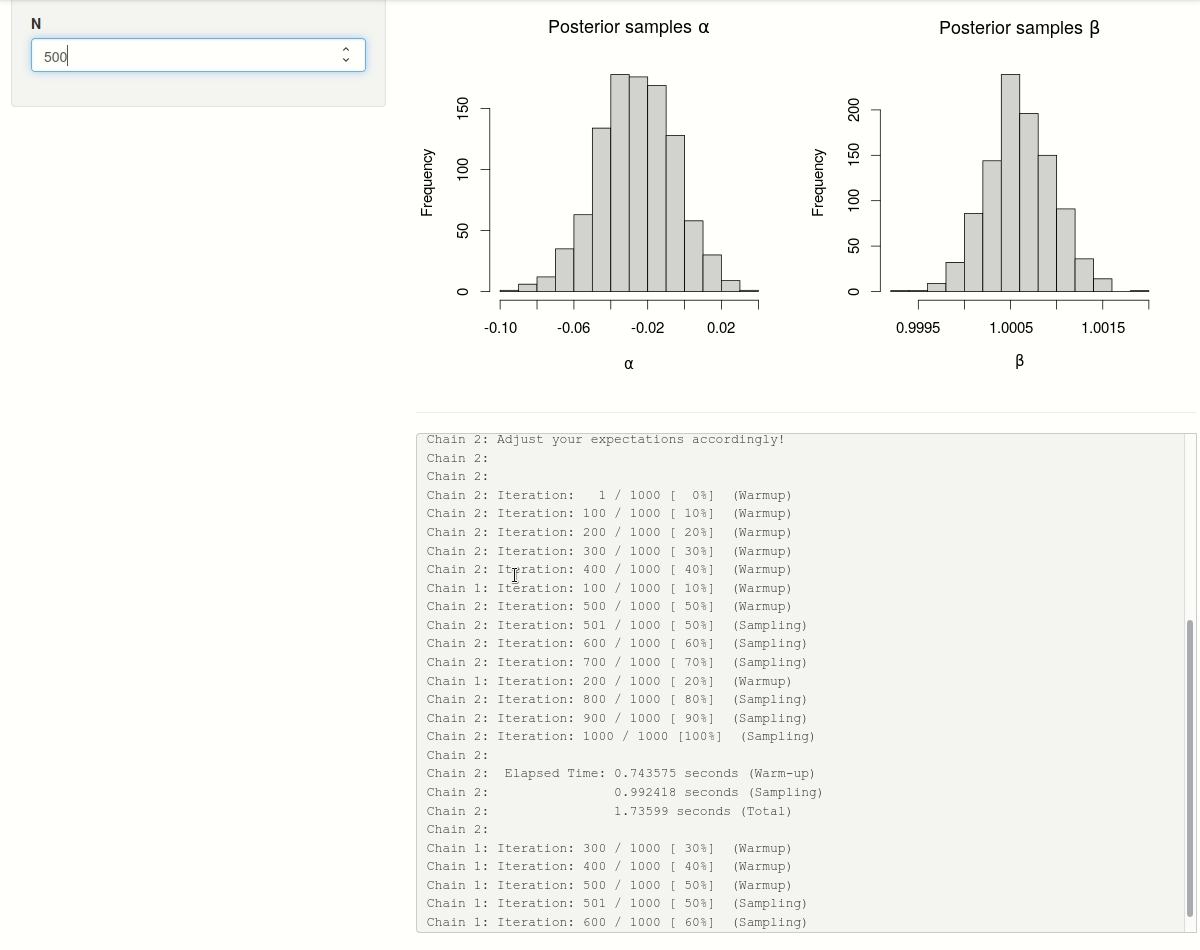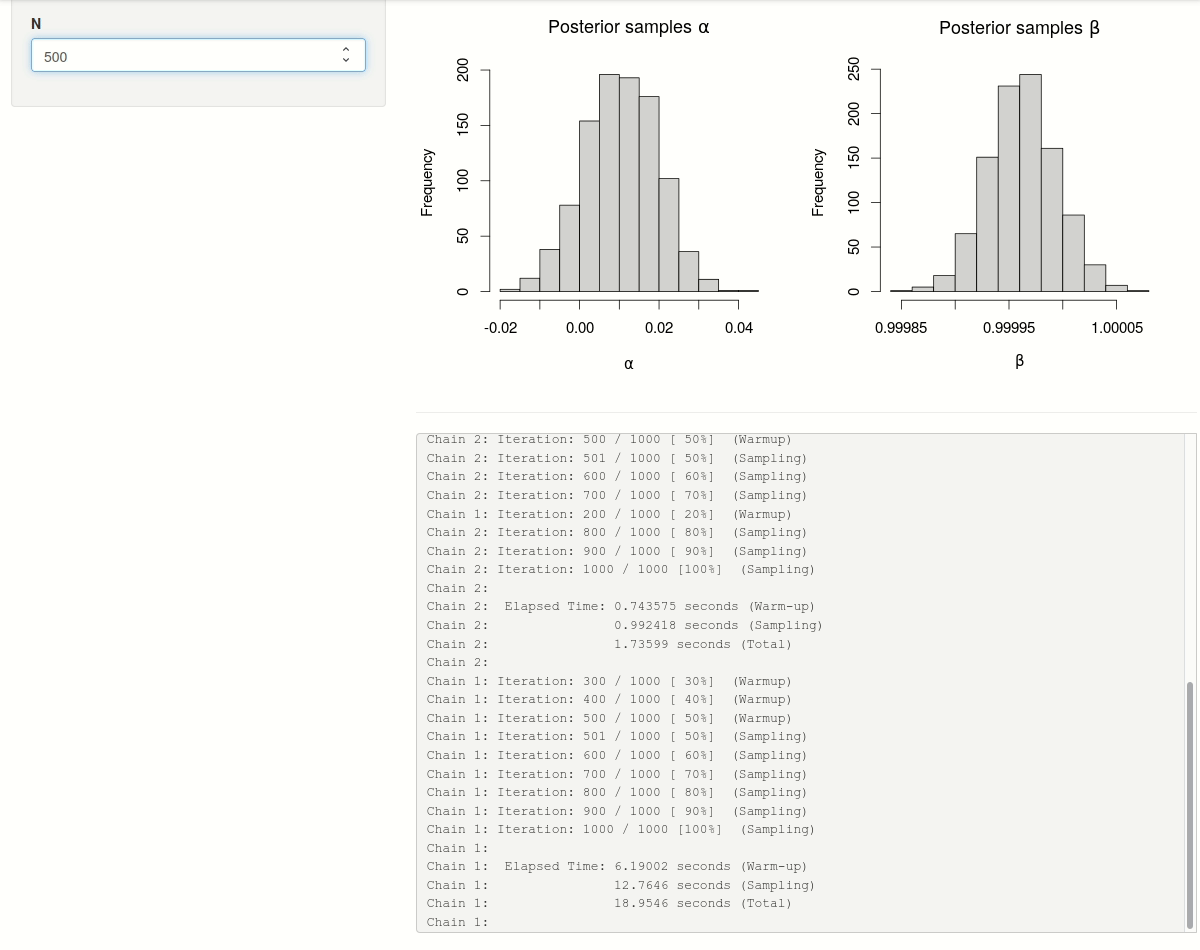
Figure 1: Progress of sampling iterations with two chains (in parallel) on a multi-core processor
![Progress of sampling iterations with two chains (in sequence) on a single-core processor[^3]](https://jchau.org/2021/02/02/tracking-stan-sampling-progress-shiny/index_files/figure-html/app2.gif)
Figure 2: Progress of sampling iterations with two chains (in sequence) on a single-core processor3
Session Info
#> R version 4.0.2 (2020-06-22)
#> Platform: x86_64-pc-linux-gnu (64-bit)
#> Running under: Ubuntu 18.04.5 LTS
#>
#> Matrix products: default
#> BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.7.1
#> LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.7.1
#>
#> locale:
#> [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
#> [3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
#> [5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
#> [7] LC_PAPER=en_US.UTF-8 LC_NAME=C
#> [9] LC_ADDRESS=C LC_TELEPHONE=C
#> [11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] callr_3.5.1
#>
#> loaded via a namespace (and not attached):
#> [1] rstan_2.21.2 tidyselect_1.1.0 xfun_0.22
#> [4] bslib_0.2.4 purrr_0.3.4 V8_3.4.0
#> [7] colorspace_2.0-0 vctrs_0.3.6 generics_0.1.0
#> [10] htmltools_0.5.1.1 stats4_4.0.2 loo_2.4.1
#> [13] yaml_2.2.1 rlang_0.4.10 pkgbuild_1.2.0
#> [16] jquerylib_0.1.3 pillar_1.4.7 DBI_1.1.1
#> [19] glue_1.4.2 withr_2.4.1 RColorBrewer_1.1-2
#> [22] matrixStats_0.58.0 lifecycle_0.2.0 stringr_1.4.0
#> [25] munsell_0.5.0 blogdown_1.2 gtable_0.3.0
#> [28] visNetwork_2.0.9 htmlwidgets_1.5.3 codetools_0.2-16
#> [31] evaluate_0.14 inline_0.3.17 knitr_1.31
#> [34] ps_1.5.0 shinyStanModels_0.1 DiagrammeR_1.0.6.1
#> [37] parallel_4.0.2 curl_4.3 highr_0.8
#> [40] Rcpp_1.0.6 scales_1.1.1 RcppParallel_5.0.2
#> [43] StanHeaders_2.21.0-7 jsonlite_1.7.2 gridExtra_2.3
#> [46] ggplot2_3.3.3 digest_0.6.27 stringi_1.5.3
#> [49] bookdown_0.21 processx_3.4.5 dplyr_1.0.4
#> [52] grid_4.0.2 cli_2.3.0 tools_4.0.2
#> [55] magrittr_2.0.1 sass_0.3.1 tibble_3.0.6
#> [58] crayon_1.4.1 pkgconfig_2.0.3 ellipsis_0.3.1
#> [61] prettyunits_1.1.1 assertthat_0.2.1 rmarkdown_2.6.6
#> [64] R6_2.5.0 compiler_4.0.2this Stan program could be made more efficient by specifying reasonable priors, but that is not the purpose of this illustration.↩︎
this approach also works when multiple chains are sampled in parallel, i.e. if the
coresargument inrstan::sampling()is larger than 1.↩︎here the shiny-app is launched in an isolated docker container with a limit on the cpu-usage (https://docs.docker.com/config/containers/resource_constraints/#cpu)↩︎