Fitting the Heckman selection model with Stan and R
Introduction
Selection bias
Selection bias occurs when sampled data or subjects in a study have been selected in a way that is not representative of the population of interest. As a consequence, conclusions made about the analyzed sample may be difficult to generalize, as the observed effects could be biased towards the sample and do not necessarily extend well to the population that we intended to analyze. In light of the current COVID-19 pandemic, we can think of multiple examples of possible selection bias: (1) the elderly or participants with certain co-morbidities may be underrepresented in a COVID-19 vaccine trial, which makes it hard to analyze the treatment effects for this segment of the population; (2) individuals with strong symptoms may be more likely to get tested than individuals with no symptoms, implying that observed health risks among tested individuals may be more severe than in the general population; (3) surveys to evaluate the government’s response in mitigating the disease spread may produce biased results, as citizens that decide to participate in a voluntary government survey may already have a more positive (or negative) view on the government’s policies and decision making.
In general, selection bias can manifest itself in different forms, such as sampling bias, self-selection bias (also a form of sampling bias), survival bias or allocation bias. The website https://catalogofbias.org/ gives a comprehensive overview of different types of bias (not only selection bias) that may be encountered in research studies and also provides a large number of illustrative examples.
Mroz dataset
A classical dataset demonstrating the effects of sampling bias is the Mroz dataset (Mroz 1987), versions of which are available in R through Mroz87 in the sampleSelection-package or Mroz in the car-package. The dataset contains observations from a 1975 Panel Study of Income Dynamics (PSID) on married women’s pay and labor force participation, as well as a number of descriptive variables, such as age, number of children and years of education. Based on the Mroz dataset, we can try to estimate a wage equation for married women in 1975 using the available descriptive variables. However, wages are only observed for women that participate in the labor-force, which introduces a form of selection bias in the observed sample. If this fact is not taken into account, the estimated effects (i.e. parameters) in the wage equation may suffer from a large bias, as a substantial proportion of married women in 1975 did not participate in the labor-force.
A simple and well-known model to correct for this specific type of selection bias is the Heckman selection model, or Heckit model, as studied in (Heckman 1979). As an excercise, we will fit the Heckman selection model using Stan (and R) and evaluate the Stan model on simulated data as well as the Mroz87 dataset.
Heckman selection model
Model setup
In the Mroz dataset, wages are only observed for individuals that are participating in the labor-force, but labor-force participation itself can be determined for each individual. The Heckman selection model uses this fact by explicitly splitting the regression problem into a model for the response of interest and a model for the binary participation decision. The participation decision is always observed, but the response of interest is only observed if the participation decision is non-zero, thereby accounting for the biased sampling process. More precisely, the original Heckman selection model as in (Heckman 1979) is defined by the following two regression equations:
- An outcome equation that represents the response of interest \(\boldsymbol{Y} = (Y_1,\ldots,Y_N)' \in \mathbb{R}^N\) by a linear model based on the observed covariates \(\boldsymbol{X} \in \mathbb{R}^{N \times p}\), \[ Y_i = X_i' \boldsymbol{\beta} + \epsilon_i, \quad \text{for}\ i = 1,\ldots,N \]
- A selection equation that models a binary participation decision \(\boldsymbol{D} = (D_1,\ldots,D_N) \in \mathbb{R}^N\) based on a second set of observed covariates \(\boldsymbol{Z} \in \mathbb{R}^{N \times q}\), \[ D_i = \boldsymbol{1}\{ Z_i'\boldsymbol{\gamma} + \eta_i > 0 \} \]
The covariates \(\boldsymbol{X}\), \(\boldsymbol{Z}\) and the participation decision \(\boldsymbol{D}\) are always observed, but the response of interest \(Y_i\) for individual \(i\) is only observed if \(D_i = 1\). In addition, the original Heckman model assumes joint normality for the error terms:
\[ \begin{pmatrix} \epsilon_i \\ \eta_i \end{pmatrix} \ \overset{\text{iid}}{\sim} \ N\left( \begin{pmatrix} 0 \\ 0 \end{pmatrix}, \begin{pmatrix} \sigma_e^2 & \rho \sigma_e \\ \rho \sigma_e & 1 \end{pmatrix} \right) \]
Note that the error terms in the two regression equations are allowed to be correlated. The variance of \(\eta_i\) is normalized to 1 as we only know the sign of \(Z_i'\boldsymbol{\gamma} + \eta_i\) in observing \(D_i\).
Likelihood derivation
The main effort in writing a Stan program for the Heckman Selection model is in deriving the joint (log-)likelihood function of the parameters \(\boldsymbol{\theta} = (\beta_1,\ldots,\beta_p, \gamma_1,\ldots,\gamma_q, \sigma_e^2, \rho)'\), given the covariates \(\boldsymbol{X}\) and \(\boldsymbol{Z}\) and the (partial) observations \(\boldsymbol{D}\) and \(\boldsymbol{Y}\).
First, since the error terms \(\epsilon_i, \eta_i\) are i.i.d. across individuals, the likelihood can be decomposed as:
\[ \begin{aligned} L(\boldsymbol{\theta}) = & \prod_{i = 1}^N \Big[ (1 - D_i) \cdot P_{\boldsymbol{\theta}}(D_i = 0 | X_i, Z_i) \\ & \quad \quad + D_i \cdot P_{\boldsymbol{\theta}}(D_i = 1 | X_i, Z_i, Y_i) \cdot P_{\boldsymbol{\theta}}(Y_i = y_i | X_i, Z_i) \Big] \end{aligned} \]
If \(D_i = 0\), we know nothing about \(Y_i\), for this reason the only contribution to the likelihood if \(D_i = 0\) is the probability that \(D_i = 0\) itself, which can be simplified to:
\[ P_{\boldsymbol{\theta}}(D_i = 0 | X_i, Z_i) \ = \ P_{\boldsymbol{\theta}}(\eta_i < -Z_i'\boldsymbol{\gamma}) \ = \ \Phi(-Z_i' \boldsymbol{\gamma}) \]
where the last step uses that the marginal distribution of \(\eta_i\) is a standard normal, i.e. \(\eta_i \sim N(0, 1)\). Also, since \(Y_i | X_i, \boldsymbol{\theta} \sim N(X_i' \boldsymbol{\beta}, \sigma_e^2)\), the probability that \(Y_i = y_i\) is given by:
\[ P_{\boldsymbol{\theta}}(Y_i = y_i | X_i, Z_i) \ = \ \frac{1}{\sigma_e}\phi\left(\frac{y_i - X_i'\boldsymbol{\beta}}{\sigma_e}\right) \]
The only term in the likelihood that remains is \(P_{\boldsymbol{\theta}}(D_i = 1 | X_i, Z_i, Y_i)\). To find this probability, we use the fact that the conditional distribution of a bivariate normal is again normal with known mean and variance, see e.g. Wikipedia. Specifically, it can be verified that:
\[ \eta_i | X_i, Z_i, Y_i \ \sim \ N\left(\rho \frac{1}{\sigma_e}(y_i - X_i'\boldsymbol{\beta}), 1-\rho^2\right) \]
Using this form for the conditional distribution of \(\eta_i\), the probability that \(D_i = 1\) can be written out as:
\[ \begin{aligned} P_{\boldsymbol{\theta}}(D_i = 1 | X_i, Z_i, Y_i) & \ = \ P_{\boldsymbol{\theta}}(\eta_i > -Z_i'\boldsymbol{\gamma} | X_i, Z_i, Y_i) \\ & \ = \ 1 - \Phi\left( \frac{-Z_i'\boldsymbol{\gamma} - \rho\frac{1}{\sigma_e}(y_i - X_i'\boldsymbol{\beta}) }{\sqrt{1 - \rho^2}} \right) \\ & \ = \ \Phi\left( \frac{Z_i'\boldsymbol{\gamma} + (\rho / \sigma_e) \cdot (y_i - X_i' \boldsymbol{\beta})}{\sqrt{1 - \rho^2}} \right) \end{aligned} \]
Combining the previous assertions, we arrive at the following expression for the log-likelihood:
\[ \begin{aligned} \ell(\boldsymbol{\theta}) \ = \ & \sum_{i = 1}^N \Big[ (1 - D_i) \cdot \ln \Phi(-Z_i'\boldsymbol{\gamma}) + D_i \cdot \Big( \ln \phi((y_i - X_i'\boldsymbol{\beta}) / \sigma_e) - \ln \sigma_e \\ & \quad \quad + \ln \Phi((Z_i'\boldsymbol{\gamma} + (\rho / \sigma_e) \cdot (y_i - X_i'\boldsymbol{\beta})) \cdot (1 - \rho^2)^{-1/2} )) \Big) \Big] \end{aligned} \]
Maximizing this log-likelihood turns out to be somewhat tricky in practice. For this reason, a two-stage estimator is considered in (Heckman 1979), which in a first step fits a probit model for the participation decision \(\boldsymbol{D}\), and in a second step fits a modified version of the outcome equation for the response of interest \(\boldsymbol{Y}\) by plugging in an inverse Mills ratio estimated in the first stage. The details of the two-stage estimator can be found in (Heckman 1979) or by a quick online search.
In contrast to the maximum likelihood estimator, the two-stage estimator is not necessarily efficient. Another disadvantage is that the estimation error in the first stage is not propagated to the second stage estimates, which makes it less straightforward1 to obtain (asymptotically) valid standard errors or confidence intervals for the parameters. With this in mind, a Bayesian sampling approach could bring something to the table. Firstly, exploring the entire space of posterior distributions should be computationally more robust than direct optimization of the likelihood. Secondly, all parameters are sampled in a joint framework (based on the derived likelihood), so we have direct access to valid credible intervals as well as other statistics of interest derived from the posteriors.
Model implementation in Stan
The following Stan program implements the Heckman selection model by directly incrementing the target total log probability function based on the derived log-likelihood:
data {
// dimensions
int<lower=1> N;
int<lower=1, upper=N> N_y;
int<lower=1> p;
int<lower=1> q;
// covariates
matrix[N_y, p] X;
matrix[N, q] Z;
// responses
int<lower=0, upper=1> D[N];
vector[N_y] y;
}
parameters {
vector[p] beta;
vector[q] gamma;
real<lower=-1,upper=1> rho;
real<lower=0> sigma_e;
}
model {
// naive (truncated) priors
beta ~ normal(0, 1);
gamma ~ normal(0, 1);
rho ~ normal(0, 0.25);
sigma_e ~ normal(0, 1);
{
// log-likelihood
vector[N_y] Xb = X * beta;
vector[N] Zg = Z * gamma;
int ny = 1;
for(n in 1:N) {
if(D[n] > 0) {
target += normal_lpdf(y[ny] | Xb[ny], sigma_e) + log(Phi((Zg[n] + rho / sigma_e * (y[ny] - Xb[ny])) / sqrt(1 - rho^2)));
ny += 1;
}
else {
target += log(Phi(-Zg[n]));
}
}
}
}
Simulated data
Saving the Stan program to a file heckman.stan, we first compile the model in R with rstan::stan_model():
library(rstan)
## compile the model
heckman_model <- stan_model(file = "heckman.stan")Next, we generate a simulated dataset and check the parameter estimates obtained by fitting the Stan model. The simulated data is generated from the exact same Heckman selection model setup as described above. The parameters and covariate matrices have been selected to induce a certain degree of correlation between the participation decision \(D_i\) and the response \(Y_i\), and the total number individuals with an observed participation decision \(D_i\) is set to \(N = 512\). Note that all responses \(Y_i\) for which \(D_i = 0\) are discarded from the simulated data2, as these responses cannot be observed in practice.
## parameters
N <- 512
beta <- c(0.5, -0.5)
gamma <- c(0.5, -2.5)
sigma_e <- 1
rho <- 0.3
## simulate correlated covariates and noise
set.seed(0)
X <- cbind(rep(1, N), rnorm(N))
Z <- X
Sigma <- matrix(c(sigma_e^2, rho * sigma_e, rho * sigma_e, 1), ncol = 2)
e <- MASS::mvrnorm(N, mu = c(0, 0), Sigma = Sigma)
## generate responses
D <- 1L * c(Z %*% gamma + e[, 2] > 0)
y <- (X %*% beta + e[, 1])[D > 0]
## fit model to simulated data
model_fit <- sampling(
object = heckman_model,
data = list(N = N, N_y = length(y), p = length(beta), q = length(gamma), X = X[D > 0, ], Z = Z, D = D, y = y)
)
#>
#> SAMPLING FOR MODEL 'heckman' NOW (CHAIN 1).
#> Chain 1:
#> Chain 1: Gradient evaluation took 0.000162 seconds
#> Chain 1: 1000 transitions using 10 leapfrog steps per transition would take 1.62 seconds.
#> Chain 1: Adjust your expectations accordingly!
#> Chain 1:
#> Chain 1:
#> Chain 1: Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 1: Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 1: Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 1: Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 1: Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 1: Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 1: Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 1: Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 1: Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 1: Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 1: Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 1: Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 1:
#> Chain 1: Elapsed Time: 1.59704 seconds (Warm-up)
#> Chain 1: 1.63941 seconds (Sampling)
#> Chain 1: 3.23645 seconds (Total)
#> Chain 1:
#>
#> SAMPLING FOR MODEL 'heckman' NOW (CHAIN 2).
#> Chain 2:
#> Chain 2: Gradient evaluation took 0.000129 seconds
#> Chain 2: 1000 transitions using 10 leapfrog steps per transition would take 1.29 seconds.
#> Chain 2: Adjust your expectations accordingly!
#> Chain 2:
#> Chain 2:
#> Chain 2: Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 2: Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 2: Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 2: Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 2: Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 2: Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 2: Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 2: Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 2: Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 2: Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 2: Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 2: Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 2:
#> Chain 2: Elapsed Time: 1.85449 seconds (Warm-up)
#> Chain 2: 1.57367 seconds (Sampling)
#> Chain 2: 3.42817 seconds (Total)
#> Chain 2:
#>
#> SAMPLING FOR MODEL 'heckman' NOW (CHAIN 3).
#> Chain 3:
#> Chain 3: Gradient evaluation took 0.000146 seconds
#> Chain 3: 1000 transitions using 10 leapfrog steps per transition would take 1.46 seconds.
#> Chain 3: Adjust your expectations accordingly!
#> Chain 3:
#> Chain 3:
#> Chain 3: Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 3: Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 3: Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 3: Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 3: Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 3: Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 3: Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 3: Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 3: Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 3: Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 3: Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 3: Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 3:
#> Chain 3: Elapsed Time: 2.09832 seconds (Warm-up)
#> Chain 3: 2.04804 seconds (Sampling)
#> Chain 3: 4.14636 seconds (Total)
#> Chain 3:
#>
#> SAMPLING FOR MODEL 'heckman' NOW (CHAIN 4).
#> Chain 4:
#> Chain 4: Gradient evaluation took 0.000136 seconds
#> Chain 4: 1000 transitions using 10 leapfrog steps per transition would take 1.36 seconds.
#> Chain 4: Adjust your expectations accordingly!
#> Chain 4:
#> Chain 4:
#> Chain 4: Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 4: Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 4: Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 4: Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 4: Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 4: Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 4: Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 4: Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 4: Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 4: Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 4: Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 4: Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 4:
#> Chain 4: Elapsed Time: 2.22932 seconds (Warm-up)
#> Chain 4: 1.72023 seconds (Sampling)
#> Chain 4: 3.94955 seconds (Total)
#> Chain 4:
model_fit
#> Inference for Stan model: heckman.
#> 4 chains, each with iter=2000; warmup=1000; thin=1;
#> post-warmup draws per chain=1000, total post-warmup draws=4000.
#>
#> mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff
#> beta[1] 0.54 0.00 0.12 0.29 0.45 0.53 0.61 0.78 1748
#> beta[2] -0.38 0.00 0.11 -0.61 -0.46 -0.38 -0.30 -0.15 1967
#> gamma[1] 0.28 0.00 0.09 0.11 0.22 0.28 0.34 0.45 3357
#> gamma[2] -2.42 0.00 0.20 -2.84 -2.56 -2.41 -2.28 -2.04 3302
#> rho 0.19 0.00 0.15 -0.13 0.09 0.19 0.29 0.48 1869
#> sigma_e 0.96 0.00 0.04 0.89 0.94 0.96 0.99 1.05 3296
#> lp__ -528.41 0.04 1.71 -532.69 -529.35 -528.07 -527.15 -526.09 1800
#> Rhat
#> beta[1] 1
#> beta[2] 1
#> gamma[1] 1
#> gamma[2] 1
#> rho 1
#> sigma_e 1
#> lp__ 1
#>
#> Samples were drawn using NUTS(diag_e) at Mon Apr 12 09:03:23 2021.
#> For each parameter, n_eff is a crude measure of effective sample size,
#> and Rhat is the potential scale reduction factor on split chains (at
#> convergence, Rhat=1).Looking at the sampling results returned by rstan::sampling(), we observe no obvious sampling problems. The posterior distributions all cover the target parameters reasonably well (using a total of \(N = 512\) observations) and all Markov chains seem to have converged correctly. From the generated pairs plot of the posterior samples, we see that the posterior densities behave nicely and we cannot discern any clearly problematic regions in the sampled parameter space, (although there is a high degree of correlation between the posterior samples for the \(\beta\) parameters and the \(\rho\) parameter).
library(bayesplot)
## pairs plot of posteriors
color_scheme_set("red")
mcmc_pairs(model_fit, pars = c("beta[1]", "beta[2]", "gamma[1]", "gamma[2]", "rho", "sigma_e"), off_diag_fun = "hex")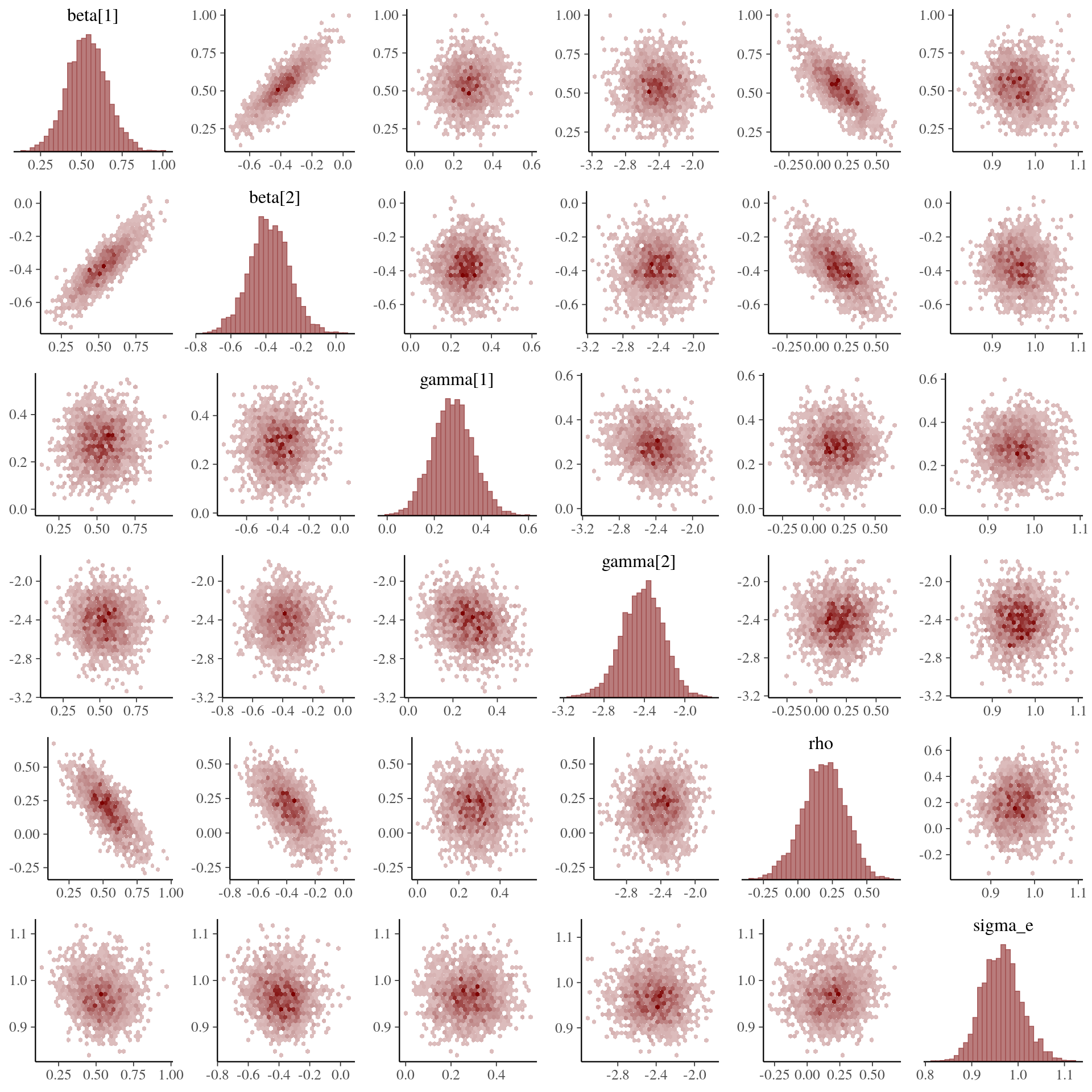
The animated plot below demonstrates the convergence of the posterior distributions to the target parameters when the number of total observations \(N\) increases. The data simulation and sampling procedures (1000 post-warmup draws across 4 individual chains) are the same as before, only the number of observations \(N\) is varied in each model fit.
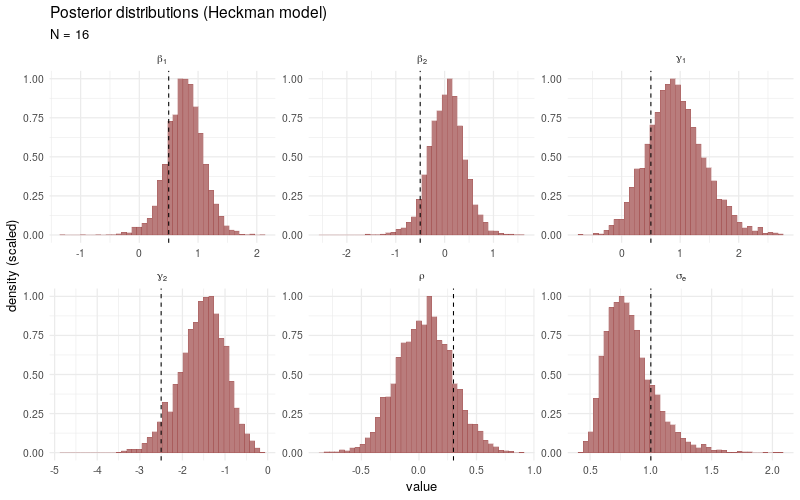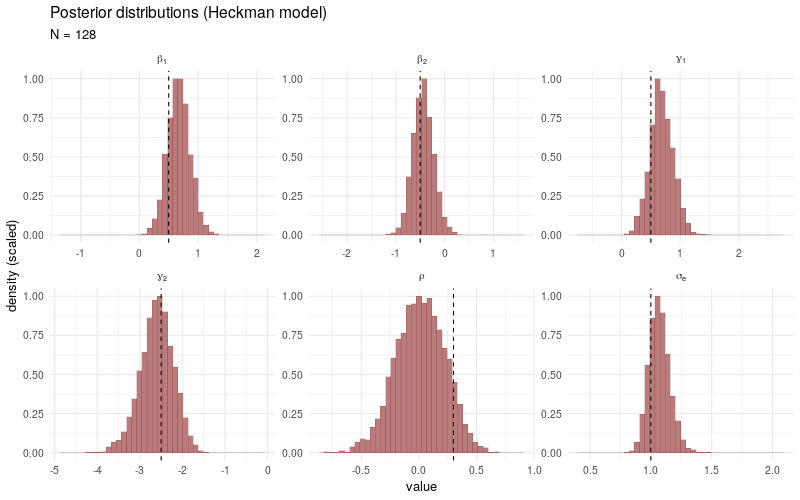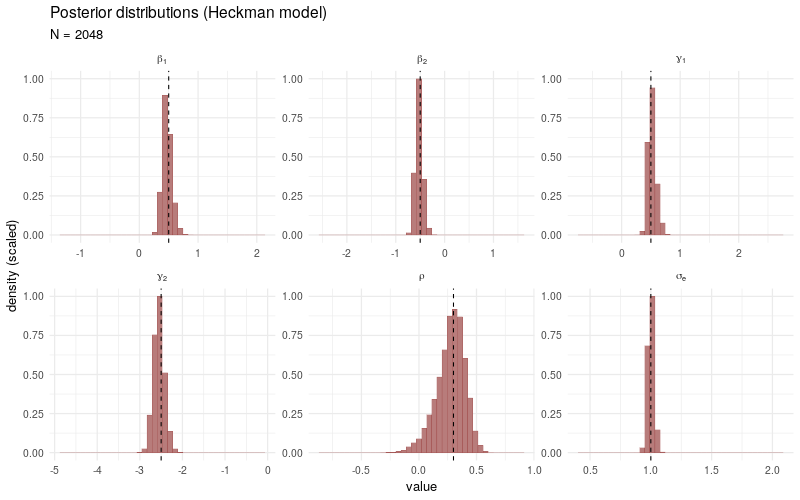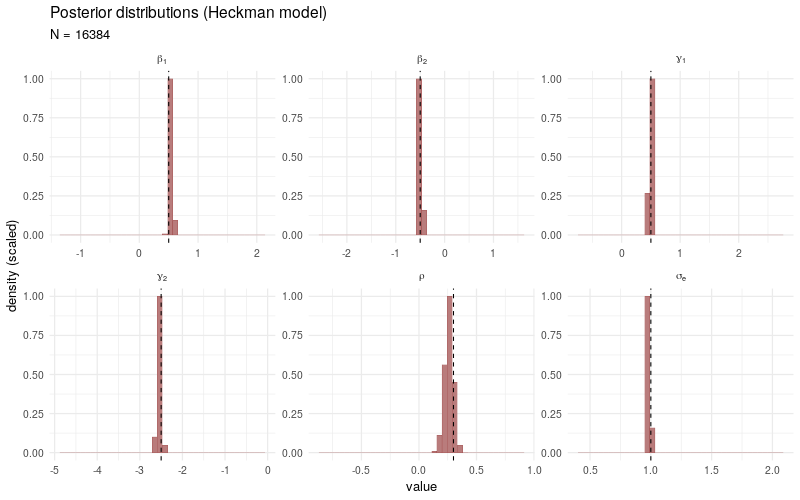
As a benchmark comparison, we generate the same animated plot showing the posterior distributions sampled from a simple linear model fitted only to the selected observations \(Y_i\) with \(D_i > 0\). As \(N\) increases, the posterior distributions no longer converge3 to the target parameters, which is due to the fact that the sampling bias introduced by the participation decision \(D_i\) is not taken into account.
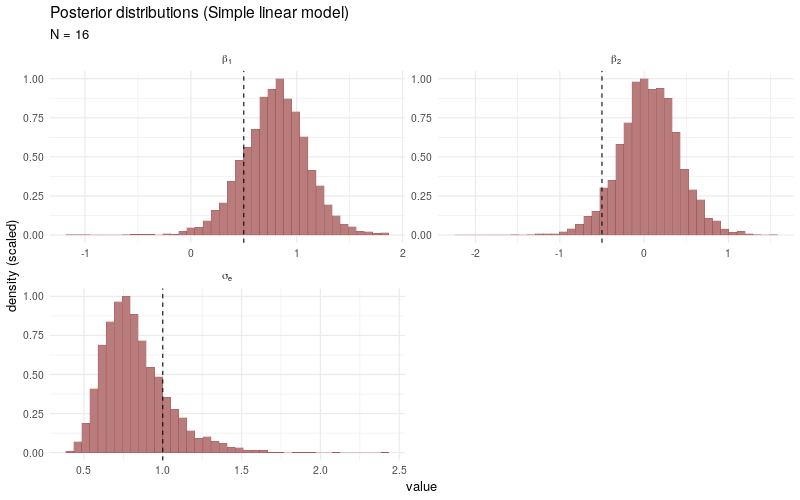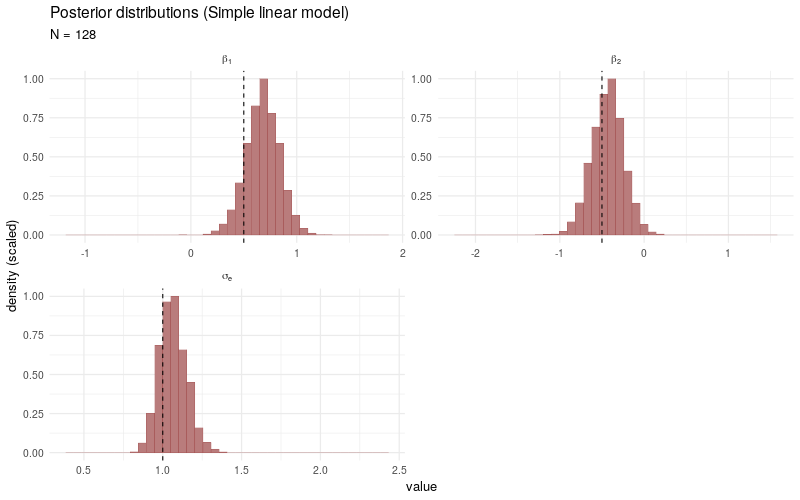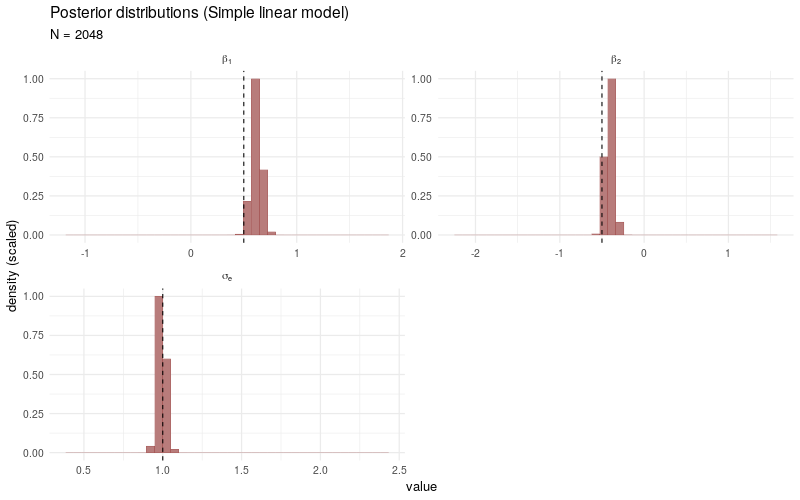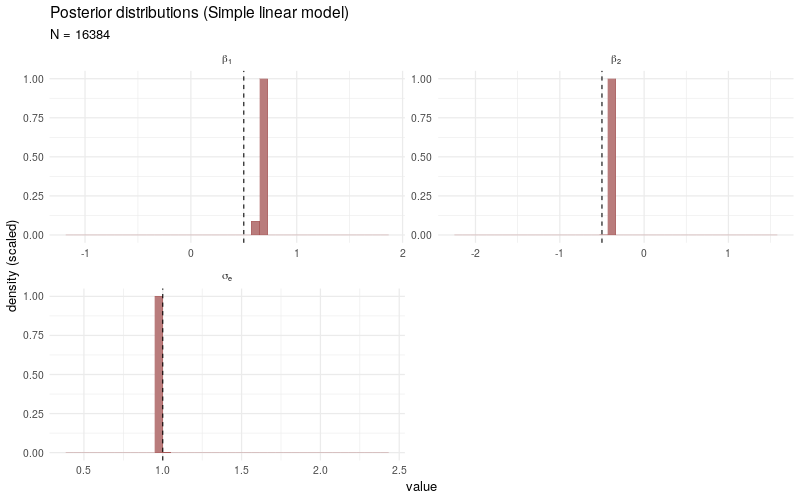
For completeness, the Stan program used to fit the simple linear models is coded as follows:
data {
int<lower=1> N_y;
int<lower=1> p;
matrix[N_y, p] X;
vector[N_y] y;
}
parameters {
vector[p] beta;
real<lower=0> sigma_e;
}
model {
beta ~ normal(0, 1);
sigma_e ~ normal(0, 1);
y ~ normal(X * beta, sigma_e);
}
Case study: Mroz dataset
As a real data example, we will estimate a log-wage equation for married women in 1975 based on the Mroz87 dataset in the same spirit as (Mroz 1987). The response of interest is the log(wage) variable, the log-wage in dollars, and the participation decision is encoded in the binary labor-force participation variable lfp.
The outcome equation for the log(wage) response is modeled as a function of: age (age in years), educ (years of education), huswage (husband’s wage in dollars) and exper (previous worked years). The participation decision is modeled based on: age, educ, hushrs (husband’s hours worked), husage (husband’s age), huswage and kids5 (number of children younger than 6).
As the Stan model is already compiled, the only work that remains is defining the model responses and covariates passed as inputs to rstan::sampling(). Note that we normalize4 the covariates to have mean zero and standard deviation 1.
library(sampleSelection)
data("Mroz87")
## covariates and response outcome equation
X <- model.matrix(~ age + educ + huswage + exper + I(exper^2), data = Mroz87)
X[, -1] <- apply(X[, -1], 2, scale) ## normalize variables
X <- X[Mroz87$lfp > 0, ]
y <- log(Mroz87$wage)[Mroz87$lfp > 0] ## response
## covariates and response selection equation
Z <- model.matrix(~ age + educ + hushrs + husage + huswage + kids5, data = Mroz87)
Z[, -1] <- apply(Z[, -1], 2, scale) ## normalize variables
D <- Mroz87$lfp ## participation decision
## fit Heckman selection model
model_fit <- sampling(
object = heckman_model,
data = list(N = length(D), N_y = length(y), p = ncol(X), q = ncol(Z), X = X, Z = Z, D = D, y = y)
)
#>
#> SAMPLING FOR MODEL 'heckman' NOW (CHAIN 1).
#> Chain 1:
#> Chain 1: Gradient evaluation took 0.000236 seconds
#> Chain 1: 1000 transitions using 10 leapfrog steps per transition would take 2.36 seconds.
#> Chain 1: Adjust your expectations accordingly!
#> Chain 1:
#> Chain 1:
#> Chain 1: Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 1: Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 1: Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 1: Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 1: Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 1: Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 1: Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 1: Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 1: Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 1: Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 1: Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 1: Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 1:
#> Chain 1: Elapsed Time: 6.42697 seconds (Warm-up)
#> Chain 1: 6.28899 seconds (Sampling)
#> Chain 1: 12.716 seconds (Total)
#> Chain 1:
#>
#> SAMPLING FOR MODEL 'heckman' NOW (CHAIN 2).
#> Chain 2:
#> Chain 2: Gradient evaluation took 0.000285 seconds
#> Chain 2: 1000 transitions using 10 leapfrog steps per transition would take 2.85 seconds.
#> Chain 2: Adjust your expectations accordingly!
#> Chain 2:
#> Chain 2:
#> Chain 2: Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 2: Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 2: Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 2: Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 2: Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 2: Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 2: Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 2: Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 2: Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 2: Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 2: Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 2: Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 2:
#> Chain 2: Elapsed Time: 6.12784 seconds (Warm-up)
#> Chain 2: 5.50429 seconds (Sampling)
#> Chain 2: 11.6321 seconds (Total)
#> Chain 2:
#>
#> SAMPLING FOR MODEL 'heckman' NOW (CHAIN 3).
#> Chain 3:
#> Chain 3: Gradient evaluation took 0.000244 seconds
#> Chain 3: 1000 transitions using 10 leapfrog steps per transition would take 2.44 seconds.
#> Chain 3: Adjust your expectations accordingly!
#> Chain 3:
#> Chain 3:
#> Chain 3: Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 3: Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 3: Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 3: Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 3: Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 3: Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 3: Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 3: Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 3: Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 3: Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 3: Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 3: Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 3:
#> Chain 3: Elapsed Time: 4.44214 seconds (Warm-up)
#> Chain 3: 4.77716 seconds (Sampling)
#> Chain 3: 9.2193 seconds (Total)
#> Chain 3:
#>
#> SAMPLING FOR MODEL 'heckman' NOW (CHAIN 4).
#> Chain 4:
#> Chain 4: Gradient evaluation took 0.000214 seconds
#> Chain 4: 1000 transitions using 10 leapfrog steps per transition would take 2.14 seconds.
#> Chain 4: Adjust your expectations accordingly!
#> Chain 4:
#> Chain 4:
#> Chain 4: Iteration: 1 / 2000 [ 0%] (Warmup)
#> Chain 4: Iteration: 200 / 2000 [ 10%] (Warmup)
#> Chain 4: Iteration: 400 / 2000 [ 20%] (Warmup)
#> Chain 4: Iteration: 600 / 2000 [ 30%] (Warmup)
#> Chain 4: Iteration: 800 / 2000 [ 40%] (Warmup)
#> Chain 4: Iteration: 1000 / 2000 [ 50%] (Warmup)
#> Chain 4: Iteration: 1001 / 2000 [ 50%] (Sampling)
#> Chain 4: Iteration: 1200 / 2000 [ 60%] (Sampling)
#> Chain 4: Iteration: 1400 / 2000 [ 70%] (Sampling)
#> Chain 4: Iteration: 1600 / 2000 [ 80%] (Sampling)
#> Chain 4: Iteration: 1800 / 2000 [ 90%] (Sampling)
#> Chain 4: Iteration: 2000 / 2000 [100%] (Sampling)
#> Chain 4:
#> Chain 4: Elapsed Time: 4.50881 seconds (Warm-up)
#> Chain 4: 5.57683 seconds (Sampling)
#> Chain 4: 10.0856 seconds (Total)
#> Chain 4:
model_fit
#> Inference for Stan model: heckman.
#> 4 chains, each with iter=2000; warmup=1000; thin=1;
#> post-warmup draws per chain=1000, total post-warmup draws=4000.
#>
#> mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff
#> beta[1] 1.12 0.00 0.08 0.96 1.06 1.11 1.17 1.29 1973
#> beta[2] -0.01 0.00 0.04 -0.09 -0.04 -0.01 0.02 0.07 4084
#> beta[3] 0.22 0.00 0.04 0.15 0.19 0.22 0.25 0.29 2948
#> beta[4] 0.08 0.00 0.04 0.00 0.05 0.08 0.11 0.16 4231
#> beta[5] 0.33 0.00 0.10 0.13 0.26 0.33 0.40 0.53 3011
#> beta[6] -0.18 0.00 0.10 -0.38 -0.25 -0.18 -0.12 0.01 2882
#> gamma[1] 0.19 0.00 0.05 0.09 0.15 0.19 0.22 0.28 4500
#> gamma[2] -0.18 0.00 0.10 -0.39 -0.25 -0.18 -0.12 0.02 2739
#> gamma[3] 0.37 0.00 0.05 0.26 0.33 0.37 0.40 0.48 3450
#> gamma[4] -0.19 0.00 0.05 -0.29 -0.23 -0.19 -0.16 -0.10 3836
#> gamma[5] -0.12 0.00 0.11 -0.33 -0.18 -0.12 -0.05 0.09 2862
#> gamma[6] -0.24 0.00 0.05 -0.34 -0.27 -0.24 -0.20 -0.13 3367
#> gamma[7] -0.48 0.00 0.06 -0.60 -0.52 -0.48 -0.44 -0.36 3705
#> rho -0.04 0.00 0.17 -0.39 -0.15 -0.03 0.08 0.27 1923
#> sigma_e 0.67 0.00 0.02 0.63 0.66 0.67 0.69 0.72 3151
#> lp__ -891.77 0.07 2.74 -898.08 -893.38 -891.41 -889.82 -887.43 1629
#> Rhat
#> beta[1] 1
#> beta[2] 1
#> beta[3] 1
#> beta[4] 1
#> beta[5] 1
#> beta[6] 1
#> gamma[1] 1
#> gamma[2] 1
#> gamma[3] 1
#> gamma[4] 1
#> gamma[5] 1
#> gamma[6] 1
#> gamma[7] 1
#> rho 1
#> sigma_e 1
#> lp__ 1
#>
#> Samples were drawn using NUTS(diag_e) at Mon Apr 12 09:04:14 2021.
#> For each parameter, n_eff is a crude measure of effective sample size,
#> and Rhat is the potential scale reduction factor on split chains (at
#> convergence, Rhat=1).Looking at the sampling results, all chains converged correctly and it seems that the model experienced no obvious issues in sampling from the posterior distributions. Below, we plot the posterior medians for the \(\beta\) and \(\gamma\) parameter vectors including 50% and 95% credible intervals:
## posterior interval plots
samples <- as.matrix(model_fit)[, c(2:6, 8:13)]
colnames(samples) <- c("age (beta)", "educ (beta)", "huswage (beta)", "exper (beta)", "exper^2 (beta)", "age (gamma)", "educ (gamma)", "hushrs (gamma)", "husage (gamma)", "huswage (gamma)", "kids5 (gamma)")
mcmc_intervals(samples, point_est = "median", prob = 0.5, prob_outer = 0.95)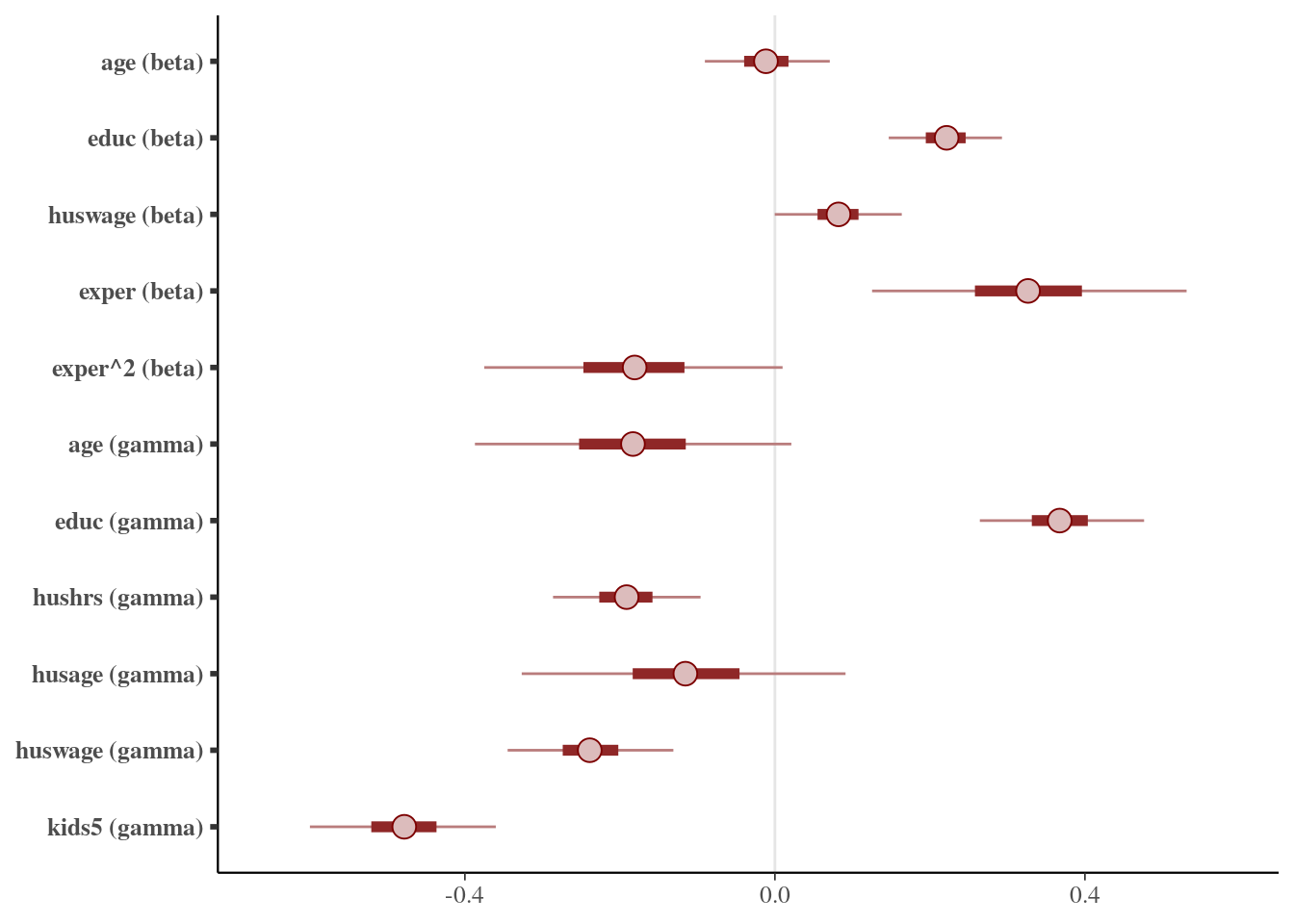
Some observations we can make from the plotted posterior intervals is that age correlates with participation in the labor-force market, but apparently has no clear effect on the wage of the observed participants. A variable that does highly correlate with the wage is the number previous years worked, which is not too surprising. Also, more years of received education has a positive effect on labor-force participation, whereas having young children has a negative effect on labor-force participation, which seems quite intuitive as well.
To conclude, we compare these results to the results obtained by fitting the same Heckman selection model using the two-stage estimator of (Heckman 1979) and direct maximum likelihood estimation with sampleSelection::heckit(). The two-stage and maximum likelihood estimators return more or less the same parameter estimates, but only the maximum likelihood estimator calculates standard errors for \(\sigma_e\) and \(\rho\). Moreover, the parameter estimates correspond very well to the posterior medians plotted above, so it seems safe to conclude that the Stan model behaves as expected.
## select variables and normalize
Mroz87_new <- Mroz87[, c("wage", "lfp", "age", "educ", "huswage", "exper", "hushrs", "husage", "kids5")]
Mroz87_new <- transform(Mroz87_new, exper_2 = exper^2)
Mroz87_new[, 3:10] <- apply(Mroz87_new[, 3:10], 2, scale)
## two-stage estimator
twostage_fit <- heckit(
selection = lfp ~ age + educ + hushrs + husage + huswage + kids5,
outcome = log(wage) ~ age + educ + huswage + exper + exper_2,
method = "2step",
data = Mroz87_new
)
summary(twostage_fit)
#> --------------------------------------------
#> Tobit 2 model (sample selection model)
#> 2-step Heckman / heckit estimation
#> 753 observations (325 censored and 428 observed)
#> 16 free parameters (df = 738)
#> Probit selection equation:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.18652 0.04857 3.841 0.000133 ***
#> age -0.18007 0.10606 -1.698 0.089979 .
#> educ 0.36817 0.05476 6.723 3.56e-11 ***
#> hushrs -0.19418 0.05084 -3.819 0.000145 ***
#> husage -0.11948 0.10745 -1.112 0.266519
#> huswage -0.23899 0.05656 -4.225 2.69e-05 ***
#> kids5 -0.48055 0.06038 -7.959 6.52e-15 ***
#> Outcome equation:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 1.11398 0.10567 10.542 < 2e-16 ***
#> age -0.01116 0.04166 -0.268 0.7889
#> educ 0.22161 0.04111 5.390 9.49e-08 ***
#> huswage 0.08056 0.04248 1.897 0.0583 .
#> exper 0.33340 0.10585 3.150 0.0017 **
#> exper_2 -0.18822 0.09925 -1.896 0.0583 .
#> Multiple R-Squared:0.1642, Adjusted R-Squared:0.1523
#> Error terms:
#> Estimate Std. Error t value Pr(>|t|)
#> invMillsRatio -0.02089 0.15408 -0.136 0.892
#> sigma 0.66058 NA NA NA
#> rho -0.03163 NA NA NA
#> --------------------------------------------
## maximum likelihood estimator
ml_fit <- heckit(
selection = lfp ~ age + educ + hushrs + husage + huswage + kids5,
outcome = log(wage) ~ age + educ + huswage + exper + exper_2,
method = "ml",
data = Mroz87_new
)
summary(ml_fit)
#> --------------------------------------------
#> Tobit 2 model (sample selection model)
#> Maximum Likelihood estimation
#> Newton-Raphson maximisation, 2 iterations
#> Return code 8: successive function values within relative tolerance limit (reltol)
#> Log-Likelihood: -882.0286
#> 753 observations (325 censored and 428 observed)
#> 15 free parameters (df = 738)
#> Probit selection equation:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.18643 0.04857 3.838 0.000135 ***
#> age -0.18025 0.10614 -1.698 0.089878 .
#> educ 0.36768 0.05488 6.700 4.14e-11 ***
#> hushrs -0.19376 0.05097 -3.801 0.000156 ***
#> husage -0.11919 0.10752 -1.109 0.267978
#> huswage -0.23891 0.05658 -4.223 2.71e-05 ***
#> kids5 -0.48083 0.06040 -7.961 6.44e-15 ***
#> Outcome equation:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 1.11200 0.10108 11.001 < 2e-16 ***
#> age -0.01142 0.04148 -0.275 0.78320
#> educ 0.22207 0.04048 5.485 5.67e-08 ***
#> huswage 0.08033 0.04232 1.898 0.05806 .
#> exper 0.33360 0.10581 3.153 0.00168 **
#> exper_2 -0.18835 0.09923 -1.898 0.05807 .
#> Error terms:
#> Estimate Std. Error t value Pr(>|t|)
#> sigma 0.66053 0.02267 29.139 <2e-16 ***
#> rho -0.02697 0.22170 -0.122 0.903
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#> --------------------------------------------Session Info
sessionInfo()
#> R version 4.0.2 (2020-06-22)
#> Platform: x86_64-pc-linux-gnu (64-bit)
#> Running under: Ubuntu 18.04.5 LTS
#>
#> Matrix products: default
#> BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.7.1
#> LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.7.1
#>
#> locale:
#> [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
#> [3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
#> [5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
#> [7] LC_PAPER=en_US.UTF-8 LC_NAME=C
#> [9] LC_ADDRESS=C LC_TELEPHONE=C
#> [11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] sampleSelection_1.2-12 maxLik_1.4-6 miscTools_0.6-26
#> [4] bayesplot_1.8.0 rstan_2.21.2 ggplot2_3.3.3
#> [7] StanHeaders_2.21.0-7
#>
#> loaded via a namespace (and not attached):
#> [1] sass_0.3.1 splines_4.0.2 VGAM_1.1-5 jsonlite_1.7.2
#> [5] carData_3.0-4 bslib_0.2.4 RcppParallel_5.0.2 Formula_1.2-4
#> [9] assertthat_0.2.1 highr_0.8 stats4_4.0.2 cellranger_1.1.0
#> [13] yaml_2.2.1 pillar_1.4.7 lattice_0.20-41 glue_1.4.2
#> [17] digest_0.6.27 colorspace_2.0-0 sandwich_3.0-0 htmltools_0.5.1.1
#> [21] Matrix_1.2-18 plyr_1.8.6 pkgconfig_2.0.3 haven_2.3.1
#> [25] bookdown_0.21 purrr_0.3.4 mvtnorm_1.1-1 scales_1.1.1
#> [29] processx_3.4.5 openxlsx_4.2.3 rio_0.5.16 tibble_3.0.6
#> [33] generics_0.1.0 farver_2.0.3 car_3.0-10 ellipsis_0.3.1
#> [37] withr_2.4.1 hexbin_1.28.2 cli_2.3.0 readxl_1.3.1
#> [41] magrittr_2.0.1 crayon_1.4.1 evaluate_0.14 ps_1.5.0
#> [45] MASS_7.3-52 forcats_0.5.1 foreign_0.8-79 pkgbuild_1.2.0
#> [49] blogdown_1.2 tools_4.0.2 loo_2.4.1 data.table_1.13.6
#> [53] prettyunits_1.1.1 hms_1.0.0 lifecycle_0.2.0 matrixStats_0.58.0
#> [57] stringr_1.4.0 V8_3.4.0 munsell_0.5.0 zip_2.1.1
#> [61] systemfit_1.1-24 callr_3.5.1 compiler_4.0.2 jquerylib_0.1.3
#> [65] rlang_0.4.10 grid_4.0.2 ggridges_0.5.3 labeling_0.4.2
#> [69] rmarkdown_2.6.6 gtable_0.3.0 codetools_0.2-16 abind_1.4-5
#> [73] inline_0.3.17 DBI_1.1.1 curl_4.3 reshape2_1.4.4
#> [77] R6_2.5.0 gridExtra_2.3 zoo_1.8-8 knitr_1.31
#> [81] dplyr_1.0.4 stringi_1.5.3 parallel_4.0.2 Rcpp_1.0.6
#> [85] vctrs_0.3.6 lmtest_0.9-38 tidyselect_1.1.0 xfun_0.22References
Heckman, J. 1979. “Sample Selection Bias as a Specification Error.” Econometrica 47(1): 153–61. https://doi.org/10.2307/1912352.
Mroz, T. 1987. “The Sensitivity of an Empirical Model of Married Women’s Hours of Work to Economic and Statistical Assumptions.” Econometrica 55(4): 765–99. https://doi.org/10.2307/1911029.
correct standard errors and confidence intervals could be obtained using resampling techniques, such as bootstrapping↩︎
this should be around half of the \(Y_i\)’s, since \(\sum_i \mathbb{E}[D_i] = N /2\) due to the way the simulated data is generated↩︎
by this we mean convergence in distribution to degenerate distributions located at the target parameters↩︎
the normalization is done with respect to all available observations, and not only the observations with
lfp > 0↩︎